
Introduction
In a recent article, I wrote about some of the failure patterns that appear repeatedly in Security Operations Centres: alert overload, detection drift, unclear ownership, and a tendency to assume detection effectiveness rather than measure it.
Those patterns are common enough that they can start to feel normal. In some environments, they are normal. Teams work hard, the technology stack is substantial, and the SOC is clearly active. Alerts are firing, analysts are responding, dashboards are populated, and reports are being produced. But activity is not the same thing as effectiveness.
That raises a more useful follow-up question: What do effective SOCs actually do differently?
The answer is usually not that they buy entirely different tools. In many cases, they are using the same platforms as everyone else. The difference is in how they think about detection, how they measure performance, and how they treat the role of detection engineering within the wider security function.
They distinguish activity from effectiveness
Most SOCs are very good at measuring operational activity. They can tell you how many alerts were generated last week. They can show incident volumes, analyst workloads, queue sizes, escalation rates, and mean response times. These metrics are useful. They tell you something about throughput, pressure, and operational tempo.
What they do not always tell you is whether the SOC is reliably detecting the behaviours it is supposed to detect.
A high number of alerts does not prove strong coverage. A full dashboard does not confirm quality. A large incident count may reflect visibility, but it may also reflect noise, poor tuning, or inconsistent triage.
Effective SOCs understand this distinction clearly. They still monitor operational activity, but they do not confuse it with security performance. They ask a harder question: Are our detections actually working as intended?
That shift sounds simple, but it changes the entire operating model. It moves the conversation away from how busy the SOC is, and towards how well its automated security decisions are performing.
They treat detections as decisions, not just rules
One of the most important mindset changes in a mature SOC is recognising that a detection rule is not just a technical artefact. It is an automated decision.
Every time a rule fires, it is effectively making a judgement. It indicates that a particular combination of activities may represent malicious behaviour, suspicious intent, or a meaningful deviation worth investigating. This matters because decisions need governance.
If a detection is too broad, it produces noise. If it is too narrow, it may miss important activity. If it relies on poor telemetry, it may give false confidence. If it is never revisited, it can silently degrade as the environment around it changes.
Effective SOCs do not treat detections as static content that gets written once and then left alone. They treat them as operational decisions that require design, ownership, testing, monitoring, and ongoing improvement.
That is where many SOCs begin to separate.
Less mature environments often focus heavily on implementation: getting rules built, deployed, and firing.
More effective ones place equal importance on whether those rules remain relevant, reliable, and aligned to real threat scenarios.
They work with a detection lifecycle
A common weakness in underperforming SOCs is treating detections as isolated tasks. A request comes in, a rule gets written, it is tuned a few times, and then it becomes part of the background.
Effective SOCs work differently. They operate around a detection lifecycle.
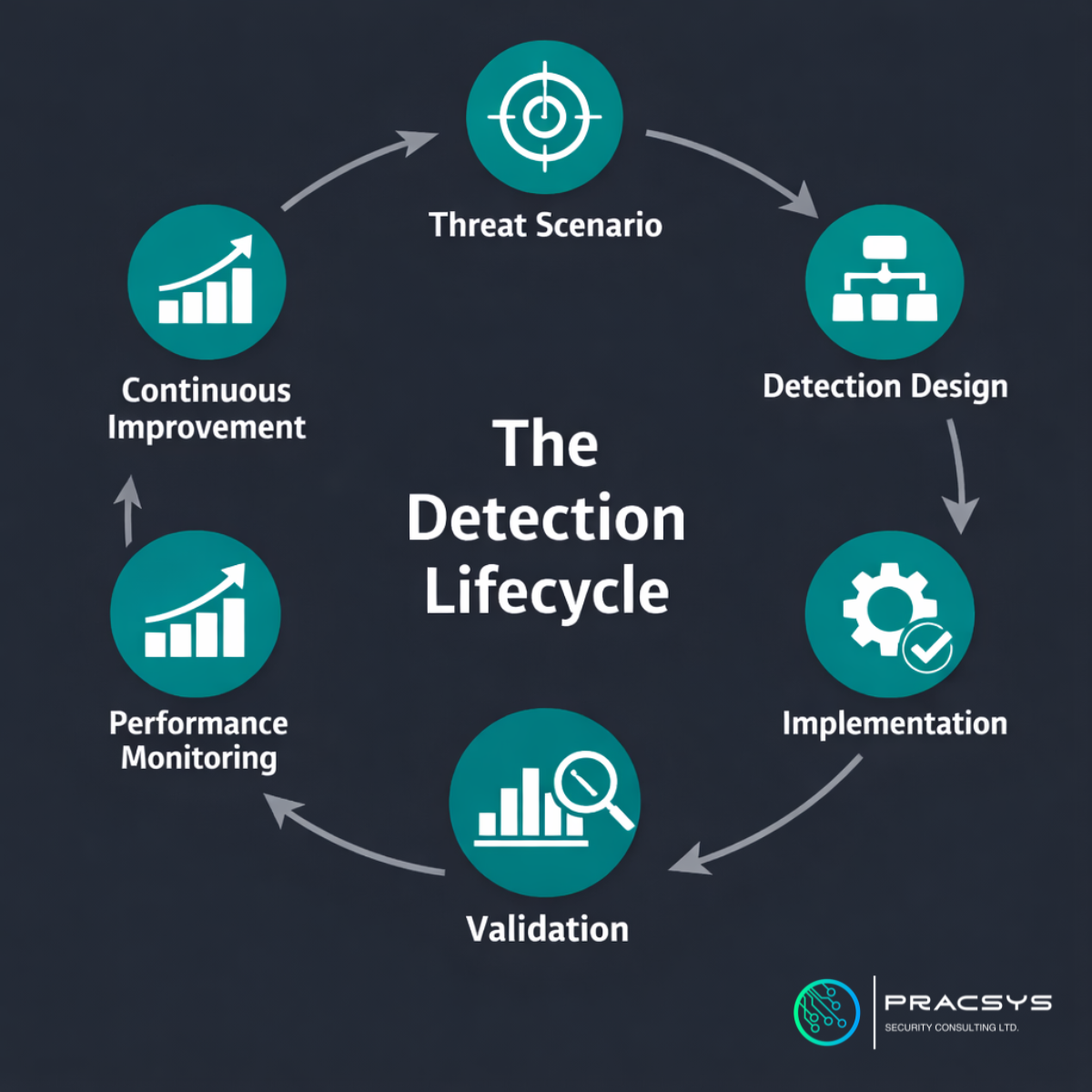
The detection lifecycle begins with a threat scenario. What behaviour are we trying to identify? What attacker action, technique, or misuse case are we trying to detect? Starting here is important because it anchors detection logic to a real purpose.
Next we proceed with detection design. Which signals are available? What telemetry is reliable? What logic is likely to identify the behaviour without overwhelming the team with false positives?
Then comes implementation. The rule is built and deployed into the SIEM, XDR, or analytics platform. For underperforming SOCs that tends to be the end of the process. In effective SOCs however, it is only the midpoint.
The next stage is validation. The team asks whether the rule actually detects what it was intended to detect. That may involve testing against known behaviours, simulating activity, reviewing historical events, or using purple-team exercises to confirm that the logic behaves as expected.
After validation comes performance monitoring. Is the alert useful? Is it actionable? Does it consistently lead to worthwhile investigations? Has the signal quality degraded? Has the environment changed in ways that affect the rule?
Finally, we have continuous improvement. Logic is refined, thresholds change, new telemetry is introduced, and coverage evolves with the threat landscape and the environment.
This lifecycle mindset is one of the clearest signs of a mature SOC. It shows that detection engineering is being treated as a living capability, not a one-off technical task.
They measure detection performance, not just workload
Another difference between effective SOCs is the quality of the metrics they choose to focus on.
Operational metrics still matter. Workload, response time, and queue pressure are all useful management indicators. But on their own, they leave a gap. They tell you how much the SOC is doing, not how well the detection layer is performing.
More mature teams introduce measures that get closer to the real question of security effectiveness.
They look at things such as detection validation coverage: how much of the rule set has actually been tested in a meaningful way. They examine alert quality: how often alerts lead to genuine analyst value rather than being filtered out as noise. They prioritise coverage against priority threat scenarios rather than assuming that a large rule library equates to broad protection. They also watch for drift: detections that once worked well but have become less useful because the environment, attacker behaviour, or data quality has changed.
These kinds of measures are harder to build than a simple count of alerts or incidents, but they are much more revealing. They start to show whether the SOC is operating from evidence or assumption.
That matters because modern SOCs are increasingly dependent on automation. Many teams rely on hundreds of rules and correlations running continuously in the background. If those automated decisions are not validated and measured, the organisation may be relying on significant invisible uncertainty.
They understand that alert fatigue is a performance problem
Alert fatigue is often described as an issue of analysts’ well-being, and it certainly has that dimension. But effective SOCs understand that it is also a detection performance issue.
When alert volumes are high and signal quality is poor, the damage is not limited to frustration or burnout. Noise changes the shape of the whole operation. Analysts spend more time filtering than investigating. Tuning gets delayed because the team is busy managing the consequences of poor-quality detections. Important signals become easier to miss because they arrive in an environment already saturated with low-value output.
Over time, this creates a subtle but serious risk. The SOC continues to appear active, but its ability to distinguish meaningful adversary behaviour from background noise is weakening.
Effective SOCs do not treat alert fatigue as inevitable. They see it as a symptom of a measurement and quality problem. Instead of accepting noise as the cost of visibility, they work to understand what alerts are genuinely useful, what detections need improvement, and where coverage is producing operational drag rather than security value.
They treat detection engineering as a governance function
Perhaps the biggest difference of all is that effective SOCs do not see detection engineering purely as an engineering activity.
It is certainly technical. It requires logic, telemetry knowledge, an understanding of attack paths, and platform expertise. But at a more strategic level, it is also a governance function.
Detection logic influences what the organisation sees, what it misses, what gets investigated, and what leadership may assume is under control. Poorly governed detections can create blind spots, wasted effort, or misplaced confidence. Strong detection governance, on the other hand, improves clarity. It helps security leaders understand not only what their tools are doing, but how much trust they should place in the outputs.
That is why the strongest SOCs tend to introduce more structure around ownership, validation, review cycles, documentation, and performance reporting. They recognise that if detections are powering automated security decisions, those decisions need oversight.
Final thought
SOC effectiveness rarely improves just because a team becomes busier or because more rules are deployed into the platform.
It improves when detection is treated as something that must be carefully designed, regularly tested, measured honestly, and continuously improved.
That is what effective SOCs do differently. They do not just monitor alerts. They work to understand the quality of the decisions behind them.
And in an environment where security operations increasingly depend on automated logic, that difference matters a great deal.